活动报告:围点第 4 期 Static Reflection
本期主题:Static Reflection
讨论时间:2025-07-20 20:00/22:30
记录时间:2025-07-24/26
问题总数:33
主持人:里缪
参与者:殇心哈、keno、逐月、枣树、Lin、安知鱼之乐、Yolo、蓝芝熊、chan、bender、ZIRQ、哼哩🦈、毛毛、Frank、冲浪的小鱼、平安是福、佐、tearshark、David(共 19 人)
前言
烈日炎炎,芭蕉冉冉,大家的探索之心难断。
作为 C++ 最新的强大特性之一,静态反射带来了诸多新玩法。本次即以此作点,发散思考,提出问题,围而攻之。
有哪些概念?哪些迷思?哪些疑惑?哪些思考?哪些启发?
且看本期讨论内容。
C++ 静态反射与其他语言(如 Java、Go、C#等)的反射有哪些核心区别?
核心区别在于反射时期,反射有编译期和运行期之分。
对比如表:
| 语言 | 反射时期 | 运行时开销? | 运行时环境 |
|---|---|---|---|
| Java | 运行期 | 有 | JVM |
| C#(.Net) | 运行期 | 有 | CLR |
| Python | 运行期 | 有 | 解释器(如 CPython) |
| Go | 运行期 | 有 | 无 |
| TypeScript | 运行期 | 有 | JavaScript引擎 |
| Kotlin | 运行期 | 有 | 基于JVM |
| D | 编译期/运行期 | 无/有 | 无 |
| C++ | 编译期 | 无 | 无 |
虚拟机语言先生成字节码,再由虚拟机解释执行或动态编译为机器码。支持运行期反射轻而易举,此类反射相对灵活,但存在运行时开销。
Native 语言直接生成二进制机器码。运行期反射会引入元数据存储和动态查询的开销,考虑到性能和控制力,不会直接提供运行期反射,而是提供静态反射,零开销,但灵活性不足。
动态语言的类型和对象结构在运行期完全可见,反射不再是独立特性,而是其对象模型自然衍生的能力。这种设计牺牲了部分性能,换来的是极强的灵活性。
平常开发中,哪些场景会用到反射?没有反射特性时,C++ 是如何应对的?
序列化/反序列化、ORM 框架、日志、调试等场景比较常见。
没有标准反射时,许多第三方库会在应用层自行收集一些元信息,提供常用结构反射功能。在《C++ 反射 第二章 探索》一文中有所介绍。
更强的反射能力,某些大型框架会提供预编译的反射机制,如 Qt 的 MOC 和 UE 的 UHT。
通过这种预编译反射机制,可以解决许多问题。
例如:
有了动态类型信息,Qt 可以知道参数类型以动态建立连接,提供信号/槽机制;UE 的蓝图系统能够访问类的成员变量和函数。
UE 的 Python 脚本或 Qt 的 QML 可以通过反射调用 C++ 对象的接口,实现跨模块通信与动态绑定。
UE 和 Qt 可以自动序列化某些标记的成员变量,还能够根据反射信息自动生成属性面板,达到动态生成 UI 的效果。
UE 编辑器利用反射动态显示对象的可编辑属性,如材质参数、Actor属性等;Qt Designer 通过反射识别控件的属性,以支持拖拽配置。
P3394R4 第 4.3 节,[[=42]] int f(); 有什么作用?
[[= expr]] 是注解的语法,expr 是一个常量表达式。
注解与属性最大的区别在于属性可以被编译器忽略,而反射要返回注解信息,不允许忽略。
因此,它们的语法很相似,可以互相理解。属性有以下语法:
// both attributes apply to the function f
[[noreturn]] void f [[noreturn]] ();可知 [[=42]] int f(); 就是附属到函数 f 的注解。
同时,可推出注解可出现的 2 个位置:
[[=41]] int g [[=42]] ();
static_assert(annotations_of(^^g).size() == 2);
static_assert([: constant_of(annotations_of(^^g)[0]) :] == 41);
static_assert([: constant_of(annotations_of(^^g)[1]) :] == 42);P3394R4 第 4.3 节,int [[=24]] f(); 这种方式为什么是错的?
本问题的完整上下文为:
// Annotations follow appertainance rules like attributes,
// but shall not appear in the attribute-specifier-seq of a type-specifier-seq or an empty-declaration:
struct [[=0]] S {}; // Okay: Appertains to S.
[[=42]] int f(); // Okay: Appertains to f.
int f[[=0]] (); // Ditto.
int [[=24]] f(); // Error: Cannot appertain to int.
[[=123]]; // Error: No applicable construct.提案规定如此,int [[=24]] f(); 注解附着于 int,而非函数 f。
不过目前的实现并没有严格约束,也能够正常编译并执行。
从第三方反射库迁移到 C++ 静态反射,有什么需要特别注意的地方?
一是要注意 C++ 版本,二是要注意从运行期到编译期的思维转换,三是要应用语法反射的优势。
C++26 反射增加了违反 ODR 的方法。有什么代码习惯可以减少使用该特性造成的违反 ODR?
静态反射不可避免地会违反 ODR。在不同的程序点反射实体 E,而每个程序点 E 的属性可能不一样,便会生成不同的代码,造成多份不同的定义。
例如,基于命名空间下的成员数量来构建分支,生成代码。因为命名空间可以重新声明和重新打开,其包含的声明集合在不同的程序点可能不同。如果两个翻译单元都包含了该实现,便可能会违反 ODR。
因此,基于实体 E 的任何可变属性生成代码分支,都不安全。此时需要识别实体结构的稳定性,不要基于不稳定结构的实体反射生成分支代码。
静态反射在面对需要运行时决策的场景,会有编译期和运行时的混合模式吗?
目前难以混合,静态反射的元信息只在编译期可用,也无法在运行期注入代码。
对于模板类的部分特化,静态反射能否区分“基础模板”与“特化版本”的元数据差异?例如,能否在编译期判断某个类型是模板的原始版本还是特化版本?
不行!
模板特化并不是模板。
is_template(^^std::vector) 会返回 true,而 is_template(^^std::vector<int>) 会返回 false。
当反射涉及多层继承(如菱形继承、虚拟继承)时,如何处理基类成员的命名冲突?静态反射是否会提供“成员来源追踪”能力(如标识某个成员来自哪个基类),以避免歧义?
members_of 并不会包含基类成员,无须多虑。
来源追踪可以自行组合 bases_of 实现,它也只会返回直接基类。
相比外部代码生成工具(如 Protobuf 的 protoc ),静态反射在“类型变更自动同步”场景中(如类成员修改后,序列化代码自动更新)有哪些不可替代的优势?又存在哪些局限性(如对复杂条件逻辑的支持)?
优势就是静态反射所带来的零开销和类型安全,并且易于优化剔除未用到的反射信息。
动态反射或其他应用层的静态反射(技巧实现)通常需要保存所有反射信息,或是需要手动在编译期解析字符串,强依赖编译器的实现,有潜在的不稳定性。此外,非语言机制外的实现都自带局限性,反射信息很难丰富。
至于类型变更自动同步,这取决于自己的设计逻辑,静态反射只是一种机制。
编译器是怎么处理静态反射的?向二进制中额外注入的信息会不会让二进制内容变得不可预测?
不会向二进制注入额外的信息。
静态反射的加入,会让静态分析器或者调试器的能力发生什么变化吗?
不影响分析器或调试器。
目前 C++ 的静态反射属于 Structural Reflection 和 Syntactic Reflection,只影响编译期的工作(对编译器的实现有影响),而分析器或调试器的目标是编译后结果。
如果反射可以写/生成代码,这还算不算“零成本”的抽象?
所谓零成本是指使用反射所引入的代码不会增加运行时开销——包括执行时间、二进制大小、内存占用等,与手动写出的等效代码相比,性能、生成代码是一样的。
提供抽象能力而不损害性能,当然算是零成本抽象。
有说法“静态反射会让 C++的模板元编程不那么黑魔法,再次降低C++的门槛”,比如:反射可以遍历所有的成员,按成员布局做序列化/反序列化。那么有没有场景还是SFINAE、偏特化的“甜点区”?
反射和模板都是一种元编程的实现方式,与模板元编程相比,反射元编程要更加灵活。
元编程都是写库/框架才会用到,普通应用层代码很少使用,也就不涉及各种高级玩法,高级玩法的门槛都不会太低。
反射用得好,模板也不会差,它们都是元编程体系的一个局部。模板元编程对于代码生成的可控性不强,而反射元编程天生就是针对这方面的,相比之下,确实简单一些。
SFINAE 负责约束模板参数,C++20 Concepts 已经解决了它存在的问题,极大简化了代码。
特化与偏特化则是一种抽象与具体的表示法,也即多态。C++ 存在数十种相关表示法,反射也是其中之一,每种表示法自有其使用空间。
反射获取函数信息,处理重载时,不同编译器、不同平台能否有办法获得统一的参数名称?
首先,参数名称可见即所得,不会像 std::type_info 那样返回 Mangled Name,代码中是什么名称就会得到什么名称。
其次,重载函数参数的名称必须一致:
int fun(int a, int b);
int fun(int const a, int b);
consteval void reflect_fun1() {
static_assert(identifier_of(parameters_of(^^fun)[0]) == "a"sv);
static_assert(identifier_of(parameters_of(^^fun)[1]) == "b"sv);
}
int fun(int const c, int b);
consteval void reflect_fun2() {
// error: inconsistent identifiers between declarations
static_assert(identifier_of(parameters_of(^^fun)[0]) == "c"sv);
}目前来看,参数数量不一致,类型不一致也会报错。
最后,在函数定义中,可以使用 variable_of 元函数,精确得到当前函数的参数名称:
int fun(int a, int b);
int fun(int const a, int b);
consteval void reflect_fun1() {
static_assert(identifier_of(parameters_of(^^fun)[0]) == "a"sv);
static_assert(identifier_of(parameters_of(^^fun)[1]) == "b"sv);
}
int fun(int const c, int b) {
// ok
static_assert(variable_of(parameters_of(^^fun)[0]) == ^^c);
static_assert(identifier_of(variable_of(parameters_of(^^fun)[0])) == "c"sv);
}哪些 C++类型不能用反射?
当前,除了表达式,都可以。
静态类型反射相比运行时反射,有实现不了的场景吗?
静态反射无法根据运行期的行为来改变代码,比如无法根据 IO 输入的字符串创建类型。
注解可能会特别长,在编程规范上有好的实践吗?
注解与属性最大的区别在于后者可被编译器忽略,其他基本都一样,所以遵循相同的规范即可。
从几篇早期材料看,反射系统的定义比 C++ 标准中实现的差别较大,是不是分广义的反射和狭义的反射?
的确存在不同类型的反射。
最广义的一种反射称为 Computational Reflection (计算反射),目的是令程序可以在运行时访问、检查并修改自身的结构和行为。这种反射涵盖了语言的运行结构(过程)、程序的表示结构(语法)、推理的知识结构(元知识)和等级嵌套的解释器(反射塔)。这是一种自指计算系统的总体框架,是最广义的反射概念,其他类型的反射都属于计算反射。
另一种反射称为 Behavioral Reflection (行为反射),可以观察和修改程序的执行过程,如环境、控制流等,具有动态改变方法行为的能力。
行为反射的一个子集称为 Procedural Reflection (过程反射),核心目的是令程序在运行时能够访问、操作、甚至修改自身的推理过程。过程指的是程序控制结构(如环境、延续、调用栈、解释器状态等),而不是数据或静态的结构。过程反射可以暂停当前执行流程,捕捉当前解释器的环境和控制流,并修改这段环境,例如注入一个调试变量,然后恢复原始程序继续执行。
还有一种反射称为 Syntactic Reflection (语法反射),这种反射可以变换或生成程序的源码或 AST,发生在编译期。用于宏展开或代码生成。
现代编译语言的反射大多属于 Structural Reflection (结构反射),可以观察和修改程序的结构,如类型、方法等。
C++26 的静态反射属于结构反射和语法反射。
早期,反射系统总是和元系统一起来讲,现在的元编程和之前的元系统有关系吗?
ZIRQ 供图:
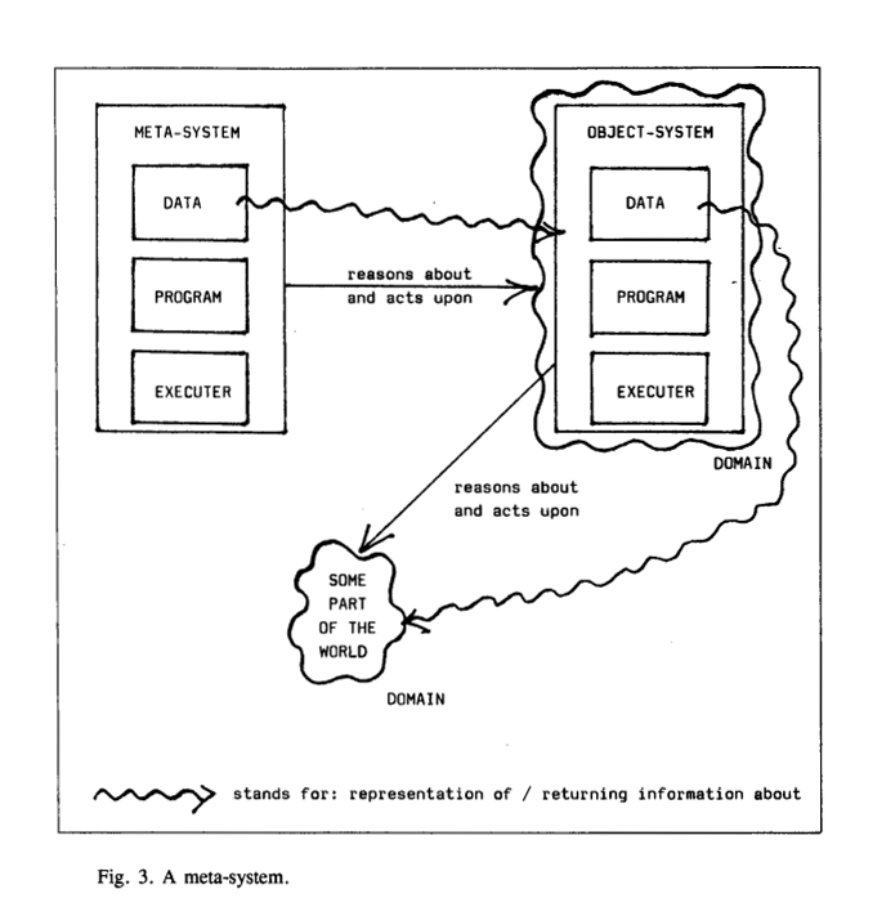
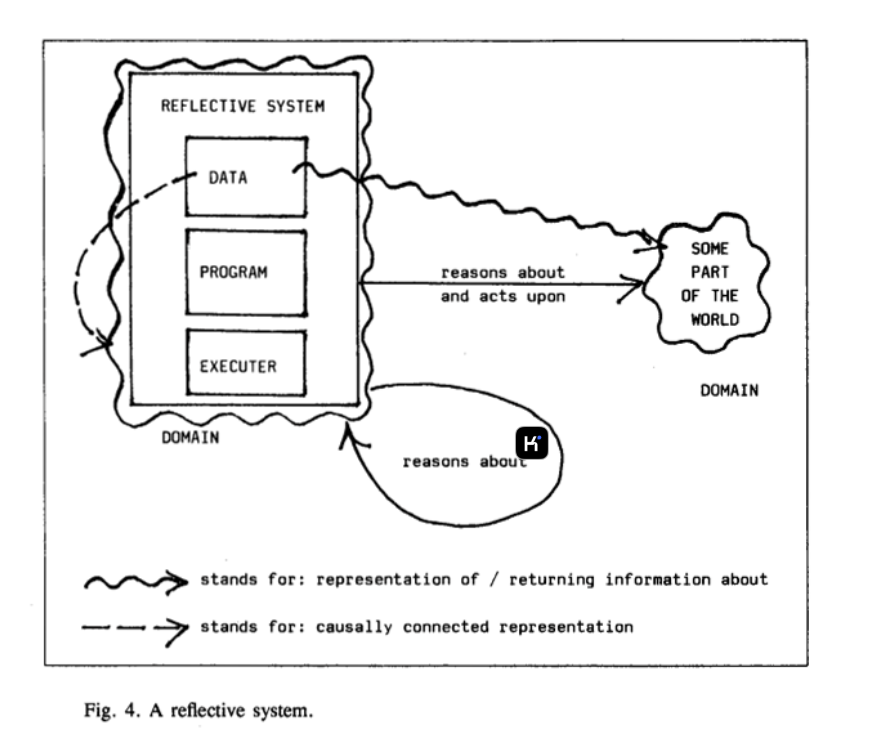
可见,一个元系统包含对象系统和元系统两部分,元系统可以获取对象系统的数据、程序、执行器的结构和状态,基于这些信息进行推理和控制,元系统是独立于对象系统的。一个反射系统只有一个系统,对象系统和元系统合并为一个整体,系统的一部分可以对自身进行观察和修改。
从元信息的处理者来看,元系统是从外部获取对象系统的信息,而反射系统是从内部本身获取信息。前者是间接,后者是直接。
对于元编程、元系统和反射这三个概念。
元编程是对于编程的编程,即编写操作程序本身的程序,程序把代码当作数据处理,在编译期生成新的代码。
元系统是一个系统对另一个系统进行建模、分析、推理、操控的系统。
反射是指系统自身拥有对自身的模型(数据、程序、执行器),可在运行时读取和修改。
元编程可以用来实现一个元系统或反射系统。
同时,反射技术本身也是一种元编程技术。
使用 substitute 元函数获得的类型信息进行对象实例化,其中的原理是什么?
直接上下文中,substitute 仅替换模板参数,不会进行实例化:
template<typename T> struct S { typename T::X x; };
constexpr auto r = substitute(^^S, std::vector{^^int}); // Okay.
typename[:r:] si; // Error: T::X is invalid for T = int.如果替换过程涉及直接上下文之外的实例化,则可能触发实例化,导致程序非法。
使用 substitute 获取的 extract 类型对象,是实例化后的真实对象吗?
extract 的作用是将反射对象转换为具体的 C++ 实体(如类型、值、函数指针等),此时可能会触发 substitute 反射类型的实例化。
静态反射在什么情况下也会带来性能损失?如果有,估计会有多大?
静态反射没有运行期开销,编译期工作增加了,编译时间肯定会长点。
P2996R13 第 4.4.7 节,Injected Declaration,具有这个特性后,类的声明替代了旧的 Lexical Ordering(粗略理解为先声明才能使用)是吗?所以声明顺序不重要了,Compile-time Evaluation 会去自动查找依赖顺序?
某些元函数具有副作用,这些元函数的求值顺序将影响程序后续的行为。
例如 define_aggregate 元函数为给定类提供定义,必须保证其效果按词法顺序立即生效:
consteval void g() {
struct S;
consteval {
define_aggregate(^^S, {});
}
S s; // S should be defined at this point.
}声明顺序和位置很重要,实际上这也是一个挺大的约束。声明必须在 consteval 块的同级作用域,跨级就会出问题:
struct S;
consteval void g() {
// Error
consteval {
define_aggregate(^^S, {});
}
S s; // S should be defined at this point.
}我写的时候感觉到不适应,同样 meta::info 类型的变量还是有不同, meta::info 可能是一种擦除,表示不同的反射,类型的反射、别名的反射、模板的反射、继承关系的反射……这和 Java 的反射类型不太一样,Java的 Class 类型就是一种,任何途径拿到了 一个类或者这个类实例的多个 Class 实例,那这些实例都是一个东西。C++26 的不同类型反射得到的东西使用的地方也不同,如何记忆?
提问者附代码:
enum class Color {
Red = 0xFF0000,
Green = 0x00FF00,
Blue = 0x0000FF
};
consteval auto enum_fields_of(std::meta::info type) {
return std::define_static_array(meta::enumerators_of(type));
}
int main() {
Color c = Color::Green;
using enum_c = decltype(c);
constexprauto enum_fields = enum_fields_of(^^Color);
template for (constexpr auto e : enum_fields) {
std::cout << is_enumerator(e) << "\n";
std::cout << is_enumerable_type(^^Color) << "\n";
std::cout << is_enumerable_type(^^decltype(c)) << "\n";
std::cout << is_enumerable_type(^^enum_c) << "\n";
// 这一行报错
std::cout << is_enumerable_type(type_of(^^enum_c)) << "\n";
std::cout << is_enumerable_type(dealias(^^enum_c)) << "\n";
std::cout << "------------------\n";
}
}对于别名,提案中明确指出需要使用 dealias() 元函数:
using X = int;
using Y = X;
static_assert(dealias(^^int) == ^^int);
static_assert(dealias(^^X) == ^^int);
static_assert(dealias(^^Y) == ^^int);因此代码中直接用 type_of 元函数于一个别名,肯定有问题。
不用记,多看、多用就行了。
在编译器正式支持反射之前,如何形成有效的代码积累?
先看提案或书中的示例熟悉各种元函数,再寻找应用场景,写一些真实有用的代码。
现有静态反射是否能在一定程度上更方便地实现某种动态反射方案?
需要结合具体动态反射场景,静态反射收集元信息更方便,可以把需要的元信息保存到运行期,但如果要保存所有元信息,那开销太大了。
反射会对当前模板编程有哪些优化?
反射和模板都是元编程的一种实现方式,模板对代码生成的控制有限,反射在这方面更加灵活。更多的优化在常量表达式时期已经带来了。
有了反射以后 std::any 是否也会变得更加实用?
不会,std::any 是在运行时保存一个类型擦除后的对象,看不到二者间的联系。
引入反射是否会像模板一样增加编译时间?或者反射的代价是什么?
开销不会凭空消失,运行期的开销没了,自然就会跑到编译期,编译时间增加是肯定的。编译器要完成的工作更多,编译器相关开发者的工作量会增加。
在没有代码注入前,怎么借用反射及有关新特性实现?
目前反射已经有 Spec API 注入模型,只是功能尚弱。注入模型是一种代码生成机制,应用层无法很好地解决。
除了(反)序列化,C++ 中还有哪些场景需要静态反射?没有反射前,大家如何解决的?
反射主要用途是使给定的程序,动态适应不同的运行情况。因为能够知道的类型信息更多,所以可以更加灵活地构建抽象逻辑。
反射也是一种定制点表示方式,没有反射前,已经存在数十种定制点表示方式了。
如果是结构反射相关功能,许多应用层自己实现的反射在以前也能满足一定的需求。
代码生成倒是在应用层无法解决,所以 Qt 和 UE 使用预编译代码生成来扩展 C++ 的反射能力。
Qt 通过 MOC 扫描头文件,识别自定义的语法标记,生成额外的 C++ 代码。这些代码与用户代码一起被编译,最终链接到程序中。这种方式有诸多局限性,如侵入式、无法反射任意类型等等,不过把功能聚焦在某些方面,也能带来极大的灵活性。
UE 通过 UHT 解析头文件,也会生成额外的 C++ 文件,包含类型的元数据,以支持蓝图交互、网络同步等引擎特性。生成的代码也和用户代码一同编译,集成到引擎的反射系统中。
它们都是在编译前生成代码,提供元信息,所以没有运行时的解析开销,但都受限于解析规则,灵活性不足。
Rust 基于 AST 的宏是反射吗?
不是。
Rust 的 Procedural Macros 源于「程序即数据」的理念,认为代码是一种数据结构,可以被程序分析和变形。它是语法级的宏变换机制,在 AST 展开阶段对代码进行修改,发生在编译期。
反射的核心是程序的自我描述与修改,而宏仅是代码生成工具,无法直接访问或修改类型信息。
模板、反射和宏其实都是元编程的一种实现方式,所以它们会有类似的功能。虽说有相似之处,却不是一个概念。