那些值得使用的 C++ Attributes
介绍
今天这篇文章,我想跟大家探索下 Attributes 这个概念。
如果你还没有听过这个概念,或是一知半解,没咋用过,那正好表明它处于一个被忽略或是低估的位置。
Meeting C++ 曾经对此做过一份调查,结果如下:
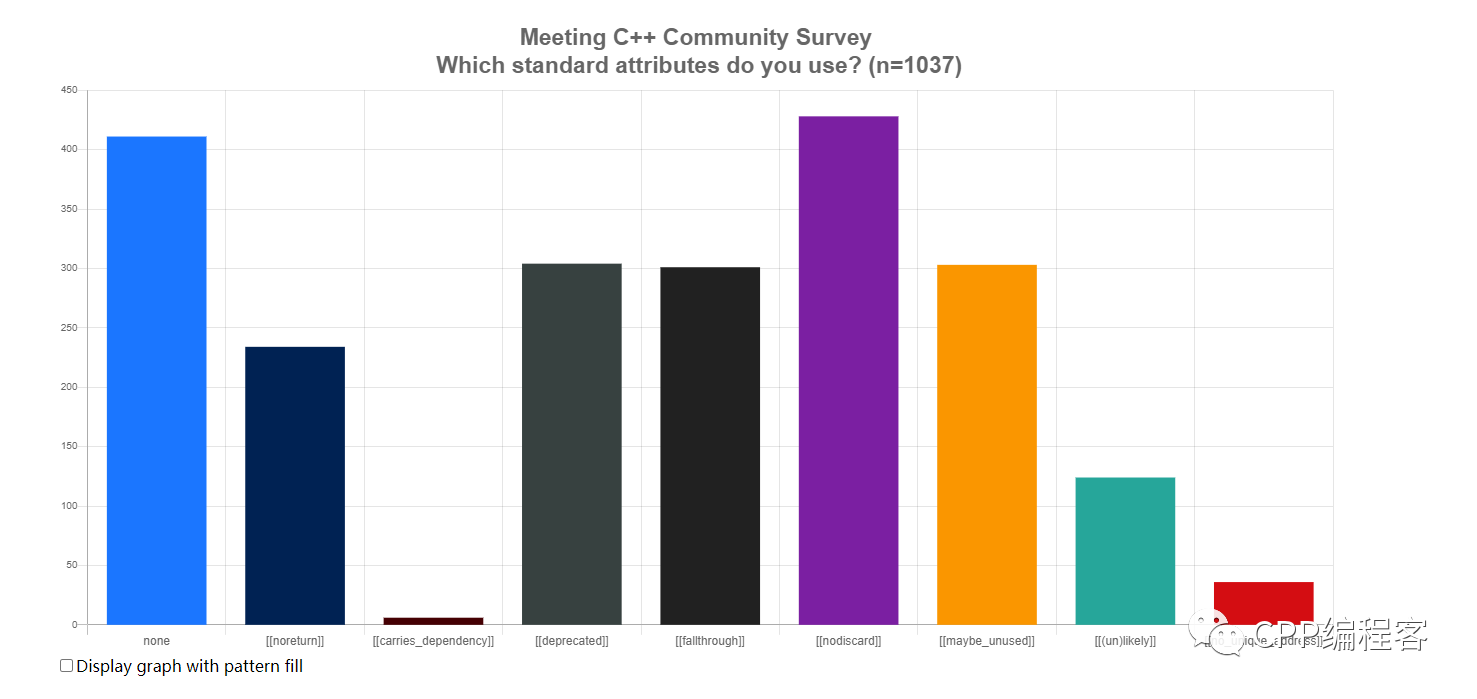
可以看出,大概一千人填写了这份问卷,其中就有半数人表示从未用过 Attributes,在被使用的 Attributes 当中,使用频率也相差较大。
你可能会认为,这些特性大都是针对写库或大型项目的人准备的,它们只是针对一些特定的场景进行优化,普通开发者几乎用不上。
然而,事实真的如此吗?
许多C++编译器不仅仅实现了语言的核心特性,还通过扩展提供了一些额外特性,比如 GNU 提供的__attribute__,MSVC 提供的 __declspec。编译器可以根据这些扩展的特性进行一些优化,但由于这些特性和平台绑定,使用这些特性就会影响代码的可移植性。因此,C++ 标准从 C++11 就开始把一些有用的扩展,慢慢添加到标准中来。
这些添加进来的扩展就叫做 C++ Attributes,标准对语法进行了统一,使用 [[attr]] 或是 [[namespace::attr]] 来指定普通的或是带有命名空间的 Attributes。
那么为什么要采用新语法,而非引入新的关键字呢?一是可以降低 Attributes 加入的障碍,二是可以防止关键字泛滥。
我们的大脑在处理事务时,是需要区分「背景」跟「主体」的,若所有的 Attributes 都被定为关键字,那么势必引发关键字泛滥。当一切都成为了主体,就相当于一切都是背景,突出不了重点。
打个比方:
在一个 RPG 游戏中,包含许多剧情,这些剧情不能整体都非常平淡,也不能整体都是高潮。因为我们对于这个游戏的整体记忆,取决于它剧情高潮和结尾时的体验。剧情越是跌宕起伏、有高有低,越能够给玩家留下深刻记忆,玩家也就越会倾向于评价这个游戏好玩。
游戏里的这些重点剧情就是「主体」,过渡剧情就是「背景」。背景是为主体服务的,去除它并不会影响整个剧情。
同样,是否使用 Attributes 也并不会影响程序的语义,也就是说,即使编译器忽略一个 Attribute 也完全没有坏处。
顺便一提,在早些时候,override 和 virtual 本来是作为 Attributes 引入的,后来发现语法又丑又极易被滥用,遂改为表示语言特性的关键字,而不是注解作用的属性。
OCW 属性模型
这里跟大家介绍一套比较有用的属性工具:「OCW属性模型」。
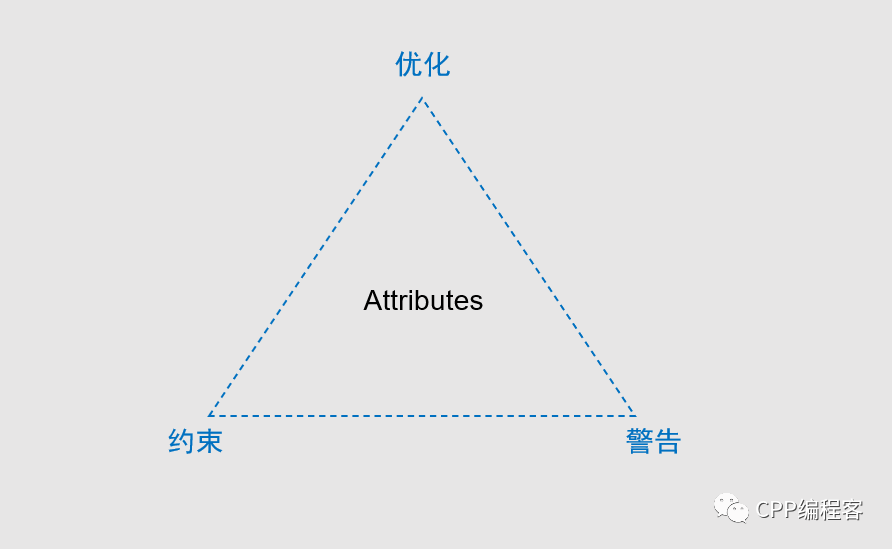
这是我自创的一个模型,它可以帮助你更好地理解、记忆跟使用 Attributes。它包含了三部分,表示 Attributes 的三方面意义:
- Optimizing(优化):对内存、并发、控制这些方面进行优化,提高性能。
- Constraints(约束):对函数、变量、类这些代码进行限制,增加安全。
- Warning(警告):对有意为之的代码产生的警告进行消除,避免误报。
下面具体来介绍一下。
第一部分,优化。指的是 Attributes 的目的是从内存布局、对齐、并发顺序、控制冒险等等这些可以提高性能的角度对代码进行优化。
例如,[[no_unique_address]] 从内存的角度优化类中数据成员的存储形式,[[(un)likely]] 从动态分支预测的角度来应对控制冒险,从而提高程序性能,[[carries_depency]] 从内存顺序的角度来优化并发能力。
第二部分,约束。有句名言叫,「设计是为了厉行约束」。好的设计应该尽可能在编译期就发现大部分错误,约束就是保证用户的使用方式与你的设计意图相符合,一些 Attributes 提供了这方面的能力。
例如,最流行的 [[nodiscard]] 可以在用户忽略重要的函数返回值时,进行提醒。 [[deprecated]] 可以标记某个组件已被弃用,并告知用户新的替代品。
第三部分,警告。C++ 包含许多奇技淫巧,所以有些代码看似无用,其实不然。然而编译期会对这些有意的代码进行误判,给出警告,当然也有技巧去消除这些警告,但 Attributes 提供了更加规范统一的做法。
例如,[[fallthrough]] 可以消除有意落空的 case 语句,就是故意省掉 case 中的 break 所导致的错误。[[maybe_unused]] 可以消除未使用的变量警告。[[noreturn]] 可以解决「调用不会返回的函数时」缺少返回值的错误。
简而言之,Attributes 涉及三个方面,优化、约束与警告。在你编写代码时,若程序想要更多的提高,可以停下来思考一下:针对每块代码可不可以从 OCW 给程序提高一些性能,让程序更加稳定。
Optimizing 优化
在前面的调查结果中,可以看到涉及优化的标准 Attributes,使用率实在太低。
这可能有这些原因。第一,优化往往只针对于特定的场景,所以注定使用场景不多。第二,这类 Attributes 牵涉的知识最是广泛,想要正确使用本就不易,普通开发者更不会轻易使用。第三,这方面教程资料尚显匮乏,许多开发者没有意识去使用这些 Attributes。
下来让我们先来对这些特性有了基本的理解。
首先来看 [[no_unique_address]],它使类数据成员可以拥有相同的地址。
有什么用呢?两点作用。
第一点,也是非常重要的一点,它为我们提供了一种创建「0字节基类子对象」的方式。
大家都知道,C++ 类(class, struct, union)对象至少会占有 1 字节的大小,即使类为空。这会导致那些没有任何数据成员的类对象大小增加,比如最著名的是使用 Policy-based Design 时产生的额外开销:
struct my_alloc { void* allocate(size_t n) { return nullptr;} };
template<class AllocPolicy>
class Foo {
private:
int i;
AllocPolicy alloc;
};这里,虽然 my_alloc 为空,但依旧占用了1字节大小,再加上 tail padding,所以 Foo 的大小由 4 字节增加到 8 字节。面对这种情况,一种解决办法是通过继承来使用策略类,而不再将它们作为数据成员。代码如下:
template<class AllocPolicy>
class Foo : AllocPolicy {
private:
int i;
};每个类对象大小至少为 1,对于基类的子对象依旧适用。所以没有任何数据成员的基类子对象并没有必要增加派生类大小,此时基类子对象的大小为 0,Foo的大小是 4 字节。
注:「基类子对象」是个术语,并不是指基类的子对象,而是指子类继承基类时,子类中所包含的基类所占的那部分内存。
然而,这种方法有什么问题呢?
许多类并没有被设计成一个基类,因此将它们作为基类也许并不合适。
[[no_unique_address]] 提供了另一种解决办法,这种方式要更加优雅:
template<class AllocPolicy>
class Foo {
int i;
[[no_unique_address]] AllocPolicy alloc;
};这里,基类子对象的大小为 0,Foo 的大小依旧为 4。
说完第一点,现在来说它的第二点作用,是告诉编译器可以重复利用 Padding Bytes 存储其他数据。看如下代码:
struct my_type { int i; char c; };
struct foo {
my_type var;
char c[3];
};思考一下,foo 的大小是多少?
foo 中包含 my_type,my_type中 int 占 4 字节,char 占 1 字节,加上 Tail Padding 的 3 字节,共 8 字节;它还包含一个 3 字节的 char,所以现在一共占 11 字节,于是再加上 1 字节的 Tail Padding,最终一共占 12 字节。
这里面 Tail Padding 一共增加了 4 字节的开销,其实 my_type 的那 3 字节开销,可以给 3 字节的 char 使用,这样总共就只需要占用 8 字节。
[[no_unique_address]] 可以实现这个目标,代码如下:
struct foo {
[[no_unique_address]] my_type var;
char c[3];
};不过就我测试,GCC 和 MSVC 似乎都还没有这种优化,MSVC 甚至第一点作用也不支持。
另外,这里还需要强调一下,[[no_unique_address]] 只能应用于「非静态的数据成员」,所以不要试图在静态变量或是全局变量之上使用它。
接下来,简单说下 [[(un)likely]] 和 [[carries_dependency]],由于这两个我打算单独写文章,所以这里只蜻蜓点水一下。
[[(un)likely]] 其实包含两个:[[unlikely]] 和 [[likely]],用于在分支代码中辅助编译器实现更加准确的「分支预测」。这到底有没有用呢?对性能提升有多大用呢?等我准备好资料数据单篇中来论。
[[carries_dependency]] 这个是关于并发的优化,涉及我们讲过的 Memory Order,还是单篇来说。
总之,优化这部分的 Attributes 的确有用,而且必不可少,在合适的场景还是推荐使用。
Constraints 约束
涉及约束的标准 Attributes,只需小做努力,程序就能获得不错的安全性,以及更加清晰地表明接口的真实意图。因而这成了使用率最高的一类 Attributes。
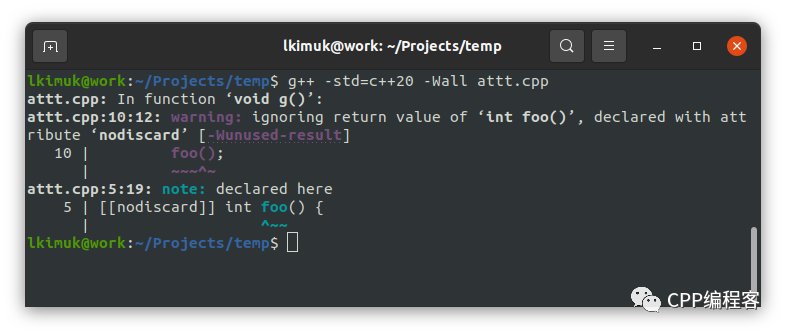
其中, [[nodiscard]] 无疑又是最常用的,它的目的在于显式地表达所定义接口的意义。可以用它来标记一个函数的返回值:
[[nodiscard]] int foo() {
return 1;
}
void g() {
foo();
}那么当你在调用时忽略 foo() 的返回值,就会引发警告,如图。
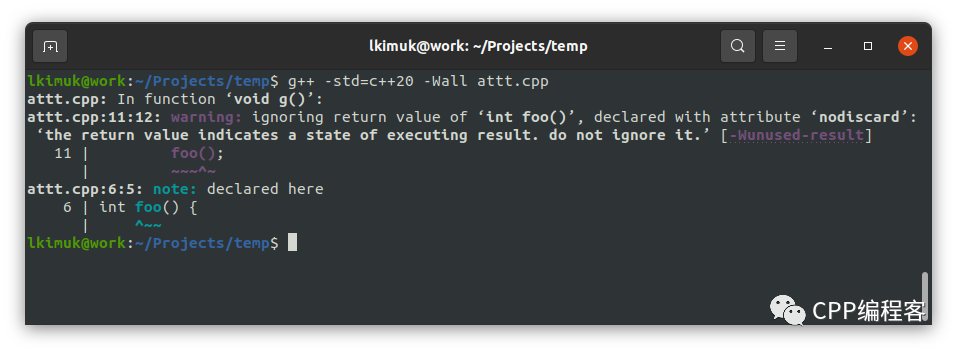
这样的警告有效,不过很模糊,应该使用扩展版本 [[nodiscard("reason")]] 来说明原因:
[[nodiscard("the return value indicates a state of executing result. do not ignore it.")]]
int foo() {
return 1;
}现在的警告要更加友好。
那么,可以在哪些地方使用它呢?这里列举一些使用场景:
- 错误信息,
error_code - 工厂方法(若使用智能指针则没必要),因为其中会使用
malloc/new这类函数分配内存。 - 返回的信息有特定作用,用户应该处理。即返回的是 non-trivial 类型,用户不处理可能引发资源泄漏之类的问题。
- 不使用返回值,通常会出现错误
std::async(),不使用返回值会导致调用变成同步的
还有一种有趣的思路,对于那些你不想让用户使用的函数,为它加上一个 [[nodiscard]] 返回值。这样,就增加了此类函数的使用成本,亦即用起来变得麻烦了,用户便会趋于放弃它。比如给 printf 加一个~
所以,不是所有地方都适合添加该属性,到处乱加可能会适得其反。
其次流行的是 [[deprecated]],它表明弃用某个组件,组件可以是函数、变量、类等等,也可以直接弃用整个命名空间下的所有组件。使用起来相当简单,代码如下:
[[deprecated]]
void foo() {}
int main() {
foo();
}因为显式指定了 [[deprecated]],所以当你试图调用 foo() 时,编译器会给出警告。
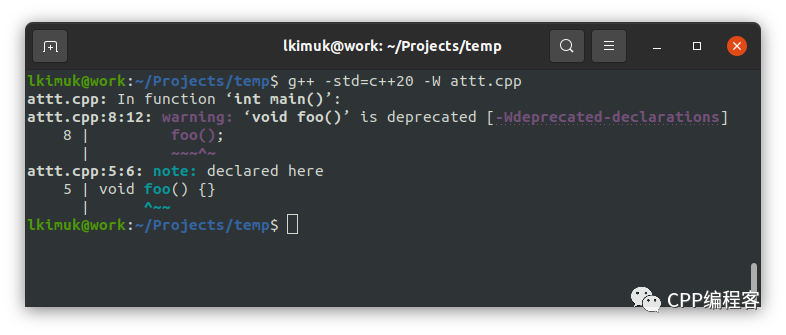
当然,只是这样,用户可能会不明就里。所以同时,你应该说明弃用的原因,以及替代品。
这使用的是扩展版的 [[deprecated("reason")]],修改上面代码如下:
[[deprecated("foo() may be unsafe. Consider using foo_safe() instead.")]]
void foo() {}现在,指定的这个原因,将会在警告时出现。

总结一下,[[nodiscard]] 比较有用,使用场景非常多,可以一定程度杜绝用户的错误行为;[[deprecated]] 可以在放弃旧的接口时,告诉用户应该使用新的接口。
Warning 警告
涉及警告的 Attributes 最为简单易用,所以使用率也还不错。
其中,[[maybe_unused]] 用于消除编译器的未使用变量警告。比如,你在 DEBUG 时期可能会设置许多断言来检测错误,而当你编译 RELEASE 版本时,就可能会产生这个警告。
void foo() {
int dummy = 1;
assert(dummy == 1);
}使用非 DEBUG 模式编译上面代码,结果如图。

通过使用 [[maybe_unused]],便可消除这个警告:
void foo() {
[[maybe_unused]] int dummy = 1;
assert(dummy == 1);
}其次,来看 [[fallthrough]],它的使用场景在于 switch-case 语句,也非常简单。看如下代码:
void test(int state) {
switch(state) {
case 1:
std::cout << "1\n";
// 没写break;
case 2:
std::cout << "2\n";
break;
default:
break;
}
}因为没写 break,编译器会给予提醒。

但有时我们是有意落空,例如:
void foo(int connState) {
switch(connState) {
default:
if(connection_timeout()) { // 如果连接超时
connState = reset_connect(); // 重置连接
[[fall_through]];
} else {
break;
}
case LISTEN:
...
}
}这里有一点需要注意,[[fallthrough]] 的下一条执行语句必须得是 case 标签。
最后,有一个比较特殊的 Attribute,就是 [[noreturn]]。
为什么说它特殊呢?因为它有两点作用,一是消除警告,二是优化。在一开始,需要明确一个观点,它并不是表明函数没有返回值,而是表明函数的控制流不会返回到调用方。
看这段代码:
// never return
void raise() {
throw "error";
}
int f(bool b) {
if(b) {
return 10;
} else {
raise();
}
}
void g() {
f(true);
std::cout << "that is impossible." << std::endl;
}控制流永远不会返回到调用方,往往意味着程序遇到了错误,需要终结或抛出异常。那么为何我要在警告这块讲解 [[noreturn]],而不是在优化那里呢?一个很重要的原因就是,优化并不是 [[noreturn]] 存在的主要目的,试想一下,这种「永远不会返回」的情况有多常见?几乎很少出现,所以通常来说也没有优化的必要。它更重要的目的在于,消除警告。看第 10 行代码,因为 raise() 永远不会返回,所以 else 分支也就没有必要写 return,但编译器并不知晓,它发现存在分支没有返回,于是给出警告。

因此,[[noreturn]] 的作用就是告诉编译器,这个函数永远不会返回,所以其后的任何代码都不会得到执行,也就自然不需要返回语句了。对于上述代码,若调用 f(false),那么第 16 行代码永远也不可能执行到,这种代码尤其应当避免。
再稍微提一下,要小心使用 [[noreturn]],如果你的函数包含了一个 while 循环,之后你却无意识地打破了这个循环,程序的行为可能会变得非常怪异。
总之,警告这类 Attributes 使用起来比较简单,用处当然也不大,但当你遇到了上述问题,应该想到可以使用它们来进行解决。
总结
通过 OCW 模型,我们可以知道,Attributes 主要是为了帮助编译器勘测代码错误,提高程序性能。
其中最有用的要数优化和约束,在平时的项目中使用这些 Attributes,可以使你的代码意图更加清晰,让你更好地掌控使用者的行为。
当你有性能需求时,试着去使用Attributes,这能帮助编译器更好地优化你的代码,生成更加高效的程序。